
Media Offline: What is it and how to deal with it?
What is media offline error in video content, and how you can detect it using automated QC solutions?
read more
Caption/Subtitle QC vs. Authoring
What is the difference between a Caption Authoring system and a Caption/Subtitle QC system? Do you need both of them as a content creator?
read more
CapMate 101 – Caption/Subtitle Files Verification and Correction Solution
Learn about Capmate – our innovative and comprehensive cloud native caption QC software that provides verification and correction of captions and subtitle files.
read more
Understanding GOP – What is “Group Of Pictures” and Why is it Important
Learn what is ‘Group of pictures’, its significance in video structuring, and how Pulsar/Quasar help in extensive GOP compliance checks.
read more
Dialog-gated Audio loudness and why it is important
Learn what is dialog gated loudness, it’s importance in video content, and how our QC products can help you detect it in an automated manner
read more
Automated detection of Mosquito Tone in media content
Learn what is “mosquito tone” in media files and how our Pulsar/Quasar QC software can detect and report on its presence.
read more
Automated Detection of Slates in Media Content
Learn about the importance of “Slate” in media files and how our Pulsar/Quasar QC software can detect and report on its presence.
read more
What is Captions Quality and how to ensure it?
Learn about quality-related aspects of Captions/Subtitles and advantages of automated verification and correction in drastically improving the efficiency of the media workflow.
read more
Ref-Q™: Reference based Automated QC
Learn about how reference based QC can help in automating the tedious manual detection of unwanted frames, incorrectly texted frames or to ensure that HDR & SDR versions are the same
read more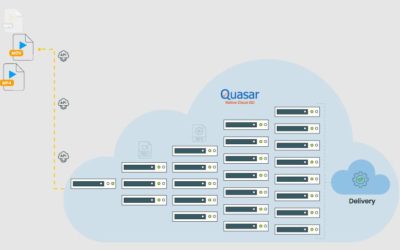
Quasar Leap – We went where no Cloud-QC service had gone before!
Learn about massive auto scaling capabilities in Quasar and how it can help performing QC of massive content volumes within a tiny fraction of time compared to static QC systems
read more
CapMate – Key Features of Our Closed Caption and Subtitle Verification and Correction Platform
Overview of Automated QC and Correction features in CapMate, our Native Cloud Captions QC & Correction platform
read more
Introducing CapMate – Taking Caption QC & Management to the Next Level
Read our experiences during customer interactions and development of CapMate, our Native Cloud Captions QC & Correction platform
read more


